10 Web Scraping
In some cases, data are available for free on the internet, but the host does not provide an API. In such cases, we can write code to retrieve the data directly from the web page. This is called web scraping.
10.1 Be Polite
Each time you visit a website, the website’s server must send the requested data to your computer. For normal web browsing by humans, this is not a problem. But often, scraping requires your code to visit many web pages. For example, say we wanted a list of poems by English poets, along with the birth dates of their authors. We might have the computer scrape the list of English poets from the Poetry Foundation, which requires clicking through 17 pages of search results, and retrieve each author’s birth date and the URL for each author’s full list of poems. We could then have the computer visit each of those URLs and retrieve the URL for each individual poem by each author. Finally, the computer would visit each poem URL and retrieve the text of the poem. In all, this process might require visiting hundreds or even thousands of web pages.
For the same reasons that APIs generally have rate limits (Chapter 9), web scraping algorithms should be polite—not, for example, requesting thousands of pages in the space of a few seconds. If you are not polite, you are likely to get banned as a bot.
To read more about web scraping etiquette and easy ways to implement it, see the relevant chapter in R for Data Science, and the homepage of the polite package.
10.2 A Simple Example
To give you a taste for what web scraping is like, we will give a simple example of scraping a single page.
The page in this case will be the blog reel of one of the authors of this book, Louis.
We will scrape the name and date of each blog post using the rvest package. First, we retrieve the raw html code of the webpage.
Then, we have to identify the name of the particular objects we are looking for. In most cases, this can be done by right clicking and pressing “Inspect Element” in the web browser.1
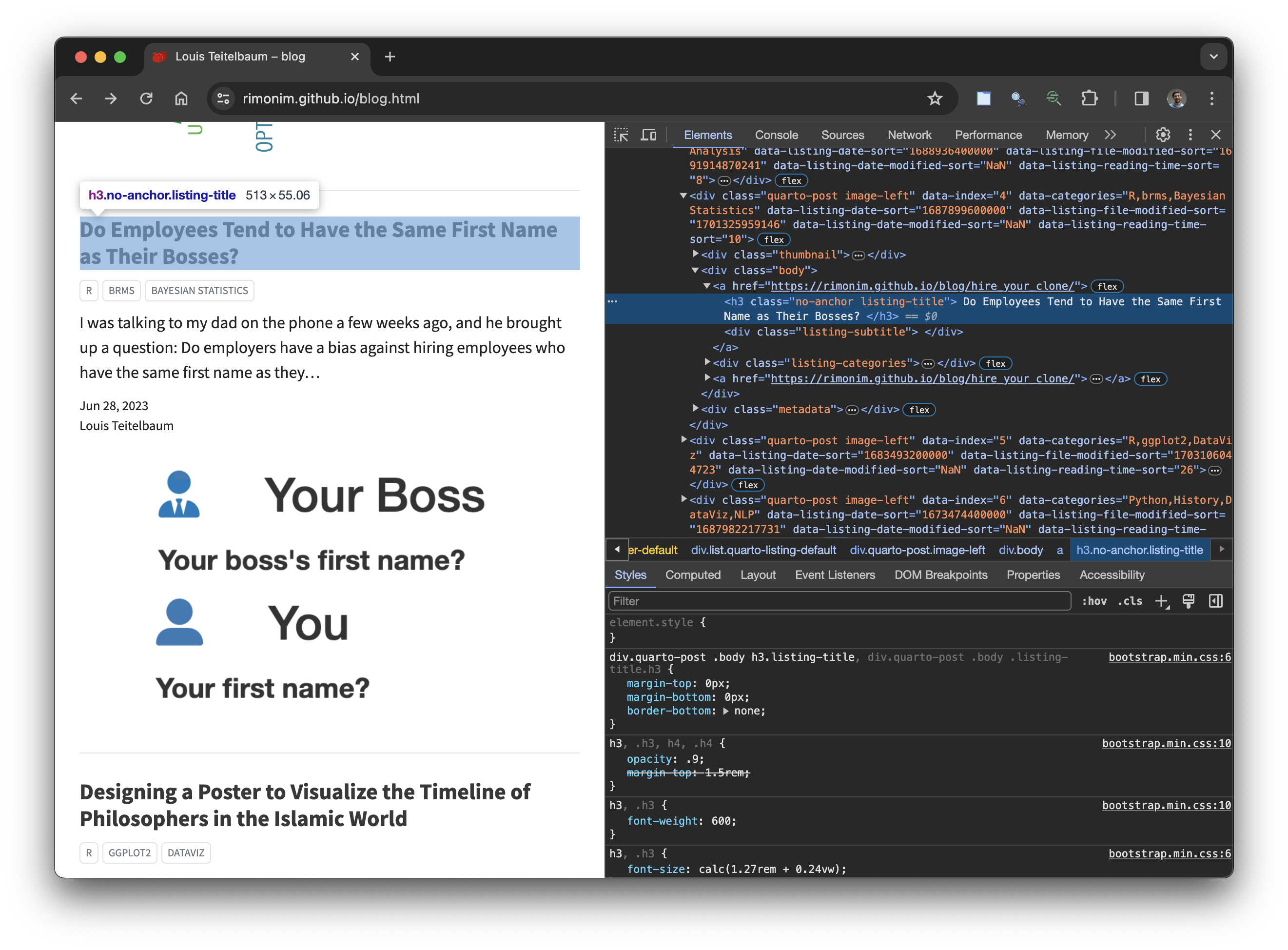
Now that we know that blog titles are called “h3.no-anchor.listing-title,” we can extract those objects from the raw html using html_elements() and convert them to regular text using html_text2().
post_titles <- html |>
html_elements("h3.no-anchor.listing-title") |>
html_text2()
head(post_titles)#> [1] "Americans Have Eight Kinds of Days"
#> [2] "Advanced Machine Learning Approaches for Detecting Trolls on Twitter"
#> [3] "Shockingly, Most Reddit Environmentalists are not Greta Thunberg"
#> [4] "Comparing Four Methods of Sentiment Analysis"
#> [5] "Do Employees Tend to Have the Same First Name as Their Bosses?"
#> [6] "Designing a Poster to Visualize the Timeline of Philosophers in the Islamic World"To build a dataset with multiple variables, we repeat this process for each variable.
posts <- tibble(
date = html |>
html_elements("div.listing-date") |>
html_text2(),
title = post_titles
)
head(posts)#> # A tibble: 6 × 2
#> date title
#> <chr> <chr>
#> 1 Aug 23, 2023 Americans Have Eight Kinds of Days
#> 2 Jul 20, 2023 Advanced Machine Learning Approaches for Detecting Trolls on Twi…
#> 3 Jul 12, 2023 Shockingly, Most Reddit Environmentalists are not Greta Thunberg
#> 4 Jul 10, 2023 Comparing Four Methods of Sentiment Analysis
#> 5 Jun 28, 2023 Do Employees Tend to Have the Same First Name as Their Bosses?
#> 6 May 8, 2023 Designing a Poster to Visualize the Timeline of Philosophers in …This is a very basic example. For a more in-depth tutorial on web scraping (including more complex examples), see the relevant chapter in R for Data Science.
Using “Inspect Element” on more complicated web pages can be difficult. For finding element names more easily, we recommend SelectorGadget↩︎