# load surprise dictionary
surprise_dict <- quanteda.sentiment::data_dictionary_NRC["surprise"]
# word2vec embeddings of dictionary words
surprise_ddr <- predict(word2vec_mod, surprise_dict$surprise)
# average dictionary embedding (weighted by frequency)
surprise_ddr <- surprise_ddr |>
average_embedding(w = "trillion_word")
# document embeddings
hippocorpus_word2vec <- hippocorpus_dfm |>
textstat_embedding(word2vec_mod) |>
bind_cols(docvars(hippocorpus_corp))
# score documents by surprise
hippocorpus_surprise_ddr <- hippocorpus_word2vec |>
get_sims(
dim_1:dim_300,
list(surprise = surprise_ddr),
method = "cosine_squished"
)20.1 Representing Psychological Constructs
In Chapter 18 we measured the surprise in texts by comparing their embeddings to that of a single word: “surprised”. But does the embedding of the word “surprised” fully capture the concept of surprise as an emotion? Faced with this question of construct validity, we have two options:
- Conduct a Validation Study: We could find or construct a dataset of texts that were rated by a human (or ideally, multiple humans) on the extent to which they reflect the emotion of surprise. We could then compare our embedding-based surprise scores to the human ratings.
- Use an Already-Validated Construct Definition: Properly validating a new measure is hard work. When possible, psychology researchers often prefer to use an existing measure that has already been carefully validated in the past.
The second option may seem difficult, since embeddings are very new to the field, so few if any validated vector representations of constructs are available. As it turns out, this is not a problem—any language-based psychological measure can be represented as a vector! Psychology has used language-based measures like dictionaries and questionnaires for over a century. To smoothly continue this existing research in the age of vector spaces, let’s consider how to translate between the two.
20.1.1 Distributed Dictionary Representation (DDR)
Let’s begin with a straightforward sort of psychological measure—the dictionary. We have already discussed dictionaries extensively in Chapter 14 and noted that psychology researchers have been constructing, validating, and publicizing dictionaries for decades (Section 14.6). But these dictionaries are designed for word counting—How do we apply them to a vector-based analysis? Garten et al. (2018) propose a simple solution: Get word embeddings (Section 18.3) for each word in the dictionary, and average them together to create a single Distributed Dictionary Representation (DDR). The dictionary construct can then be measured by comparing text embeddings to the DDR.
DDR cannot entirely replace word counts; for linguistic concepts like pronoun use or the passive voice, dictionary-based word counts are still necessary. But DDR is ideal for studies of abstract constructs like emotions, that refer to the general gist of a text rather than particular words. The rich representation of word embeddings allows DDR to capture even the subtlest associations between words and constructs, and to precisely reflect the extent to which each word is associated with each construct. It can do this even for texts that do not contain any dictionary words. Because embeddings are continuous and already calibrated to the probabilities of word use in language, DDR also avoids the difficult statistical problems that arise due to the strange distributions of word counts (Chapter 16).
Garten et al. (2018) found that DDR works best with smaller dictionaries of only the words most directly connected to the construct being measured (around 30 words worked best in their experiments). Word embeddings work by overvaluing informative words (Section 18.3.4)—a desirable property for raw texts, in which uninformative words tend to be very frequent.1 But dictionaries only include one of each word. In longer dictionaries with more infrequent, tangentially connected words, averaging word embeddings will therefore overvalue those infrequent words and skew the DDR. This can be fixed with Garten et al.’s method of picking out only the most informative words. Alternatively, it could be fixed by measuring the frequency of each dictionary word in a corpus and weighting the average embedding by that frequency. This method is actually more consistent with the way most dictionaries are validated, by counting the frequencies of dictionary words in text (Chapter 14).
Let’s measure surprise in the Hippocorpus texts by computing a DDR of the NRC Word-Emotion Association Lexicon (S. M. Mohammad & Turney, 2013; S. Mohammad & Turney, 2010), which we used in Chapter 14. To correct for word informativeness, we will weight the dictionary word embeddings by their frequency in the Google Trillion Word corpus.
With the new measure of surprise, we can retest the hypothesis that true autobiographical stories include more surprise than imagined stories.
# beta regression
surprise_mod_ddr <- betareg::betareg(
surprise ~ memType,
data = hippocorpus_surprise_ddr
)
summary(surprise_mod_ddr)#>
#> Call:
#> betareg::betareg(formula = surprise ~ memType, data = hippocorpus_surprise_ddr)
#>
#> Standardized weighted residuals 2:
#> Min 1Q Median 3Q Max
#> -4.2730 0.0030 0.1592 0.3131 0.9642
#>
#> Coefficients (mean model with logit link):
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 1.742587 0.007548 230.859 memTyperecalled -0.050964 0.010479 -4.863 1.15e-06 ***
#> memTyperetold -0.038424 0.013048 -2.945 0.00323 **
#>
#> Phi coefficients (precision model with identity link):
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 48.0008 0.8175 58.72 ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Type of estimator: ML (maximum likelihood)
#> Log-likelihood: 1.081e+04 on 4 Df
#> Pseudo R-squared: 0.004991
#> Number of iterations: 10 (BFGS) + 2 (Fisher scoring)
We again find significant differences in surprise between imagined and recalled stories, in the opposite of the expected direction. This is somewhat different from our results in Chapter 14, where we tested the same hypothesis with the same dictionary, but used word counts rather than embeddings.
20.1.1.1 DDR for Word-by-Word Analysis
Another advantage of DDR over dictionary-based word counts is that DDR enables word-by-word analysis of text. It is not very informative to count how many surprise words are in each word (it will either be one or zero), but we can compare the embedding of each word to the surprise DDR—how close are they in the vector space? This allows us to see how a construct spreads out within a single text. As an example, let’s take a single story from the Hippocorpus:
# full text as string
story <- word(hippocorpus_df$story[3], end = 140L)
cat(story)#> It seems just like yesterday but today makes five months ago it happened. I had been watching my phone like an owl for the past week. I was waiting for a work related call that my team was waiting for to close a important deal. It wasnt the call I expected though. It was for my sister was in labor with the twins. My sister is only 7 months pregnant. I got the call shortly after arriving at work. Just as fast I was back out the door and on my way to the hospital. When I arrived my sister had just delivered and I just was in awe. Even though they were a bit small they were mighty. They were the most precious things I had ever seen. I held my niece and nephew and couldnt stop crying.
To visualize surprise within this text, we can separate it into words and find the embedding of each word. Rather than averaging all of these embeddings together to get the embedding of the full text, we can compute a rolling average, averaging each word’s embedding with those of its neighbors.
# separate into vector of tokens
story <- word(hippocorpus_df$story[3], end = 140L) |>
tokens() |> as.character() |> str_to_lower()
# rolling average of embeddings
story_surprise <- predict(word2vec_mod, story, .keep_missing = TRUE) %>%
zoo::rollapply(
width = 4,
FUN = mean,
na.rm = TRUE,
by.column = TRUE,
align = "center"
)
# vector of computed surprise (cosine similarity)
story_surprise <- story_surprise |>
as.embeddings() |>
get_sims(list(surprise = surprise_ddr)) |>
pull(surprise)We can now visualize the surprise in each word of the text. Since ggplot2 makes it difficult to plot dynamically colored text in one continuous chunk, we will use ANSI color codes to print the text directly to the console.
# (see https://www.hackitu.de/termcolor256/ for info on ANSI colors)
# blue-red heat scale
ansi_scale <- c(
063, 105, 147, 189, 188, 230, 223,
224, 217, 210, 203, 196, 160, 124
)
# turn scale value into ANSI color code
map_to_ansi <- function(x, ansi_scale){
x_new <- (x - min(x, na.rm = TRUE))*((length(ansi_scale) - 1)/diff(range(x, na.rm = TRUE))) + 1
x_new
ansi_scale[round(x_new)]
}
story_surprise <- map_to_ansi(story_surprise, ansi_scale)
# print
for (i in 1:length(story_surprise)) {
if(is.na(story_surprise[i])){
cat(story[i], " ")
}else{
cat(paste0("\033[48;5;", story_surprise[i], "m", story[i], " \033[0m"))
}
}#> it seems just like yesterday but today makes five months ago it happened . i had been watching my phone like an owl for the past week . i was waiting for a work related call that my team was waiting for to close a important deal . it wasnt the call i expected though . it was for my sister was in labor with the twins . my sister is only 7 months pregnant . i got the call shortly after arriving at work . just as fast i was back out the door and on my way to the hospital . when i arrived my sister had just delivered and i just was in awe . even though they were a bit small they were mighty . they were the most precious things i had ever seen . i held my niece and nephew and couldnt
20.1.2 Contextualized Construct Representation (CCR)
Dictionaries are not the only validated psychological measures that we can apply using embeddings. With contextualized embeddings, we can extract the gist of any text and compare it to that of any other text (Chapter 19). Atari et al. (2023) propose to do this with the most popular form of psychometric scale: the questionnaire. Psychologists have been using questionnaires to measure things for over a century, and tens of thousands of validated questionnaires are now available online. The LLM embedding of a questionnaire is referred to as a Contextualized Construct Representation (CCR).
We can use CCR to measure surprise in the Hippocorpus texts. For our questionnaire, we will use an adapted version of the surprise scale used by D. Choi & Choi (2010) and I. Choi & Nisbett (2000).
surprise_items <- c(
"I was extremely surprised by the outcome of the event.",
"The outcome of the event was extremely interesting.",
"The outcome of the event was extremely new."
)
Beware of Reverse Coding!
Many questionnaires include reverse-coded items (e.g. “I often feel happy” on a depression questionnaire). The easiest way to deal with these is to manually add negations to flip their meaning (e.g. “I do not often feel happy”).
The first step in using CCR is to compute contextualized embeddings for the texts in the Hippocorpus dataset. We already did this in Chapter 19. The next step is to compute contextualized embeddings for the items in the questionnaire, and average them to produce a CCR.
# embed items (using the same model as we used before)
library(text)
sbert_embeddings <- function(texts) {
text::textEmbed(
texts,
model = "sentence-transformers/all-MiniLM-L12-v2", # model name
layers = -2, # second to last layer (default)
tokens_select = "[CLS]", # use only [CLS] token
dim_name = FALSE,
keep_token_embeddings = FALSE
)$texts[[1]]
}
# compute CCR by averaging item embeddings
surprise_ccr <- surprise_items |>
embed_docs(sbert_embeddings, output_embeddings = TRUE) |>
average_embedding()We can now measure surprise in the Hippocorpus texts by computing the cosine similarity between their embeddings and the surprise CCR.2
# score documents by surprise
hippocorpus_surprise_ccr <- hippocorpus_sbert |>
get_sims(
Dim1:Dim384,
list(surprise = surprise_ccr),
method = "cosine_squished"
)
# beta regression
surprise_mod_ccr <- betareg::betareg(
surprise ~ memType,
hippocorpus_surprise_ccr
)
summary(surprise_mod_ccr)#>
#> Call:
#> betareg::betareg(formula = surprise ~ memType, data = hippocorpus_surprise_ccr)
#>
#> Standardized weighted residuals 2:
#> Min 1Q Median 3Q Max
#> -6.1295 -0.6100 0.0520 0.6634 3.6654
#>
#> Coefficients (mean model with logit link):
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) 5.636437 0.002885 1953.487 memTyperecalled -0.020755 0.004042 -5.135 2.83e-07 ***
#> memTyperetold -0.026428 0.005016 -5.269 1.37e-07 ***
#>
#> Phi coefficients (precision model with identity link):
#> Estimate Std. Error z value Pr(>|z|)
#> (phi) 12226.6 209.2 58.43 ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Type of estimator: ML (maximum likelihood)
#> Log-likelihood: 4.187e+04 on 4 Df
#> Pseudo R-squared: 0.005735
#> Number of iterations: 59 (BFGS) + 14 (Fisher scoring)
Once again, a significant difference in surprise between remembered and recalled stories in the opposite of the expected direction. However, CCR has a fundamental problem that needs to be addressed.
Embeddings capture the overall “vibes” of a text, including its tone and dialect. With CCR, we are comparing the “vibes” of a questionnaire written by academics to the “vibes” of narratives written by Hippocorpus participants. By comparing these vectors, we are not just measuring how much surprise is in each text—we are also measuring the extent to which each text is in the style of a questionnaire written by academics. This introduces a confounding variable into our analysis—questionnaire-ness.
The questionnaire-ness problem means that CCR is most effective for analyzing texts that bear a strong similarity to the questionnaire itself. For example, if you are analyzing participant descriptions of their own values, and your questionnaire items are statements about values in the first person (as many questionnaires are), CCR is likely to work well, especially with the improvement described in Section 20.2.2 and Section 20.2.2.2. With this method, you can compare participant responses to the questionnaire without actually administering the questionnaire itself; participants can answer in their own words, which CCR will compare to the wording of the questionnaire.
20.2 Reasoning in Vector Space: Beyond Cosine Similarity and Dot Products
20.2.1 Additive Analogies
Nearly every introduction to word embeddings opens with their analogical property. This is for good reason: it is extremely cool. Embeddings can be added to each other in order to arrive at new concepts. Here’s an example, using word2vec embeddings reduced to two dimensions with PCA:
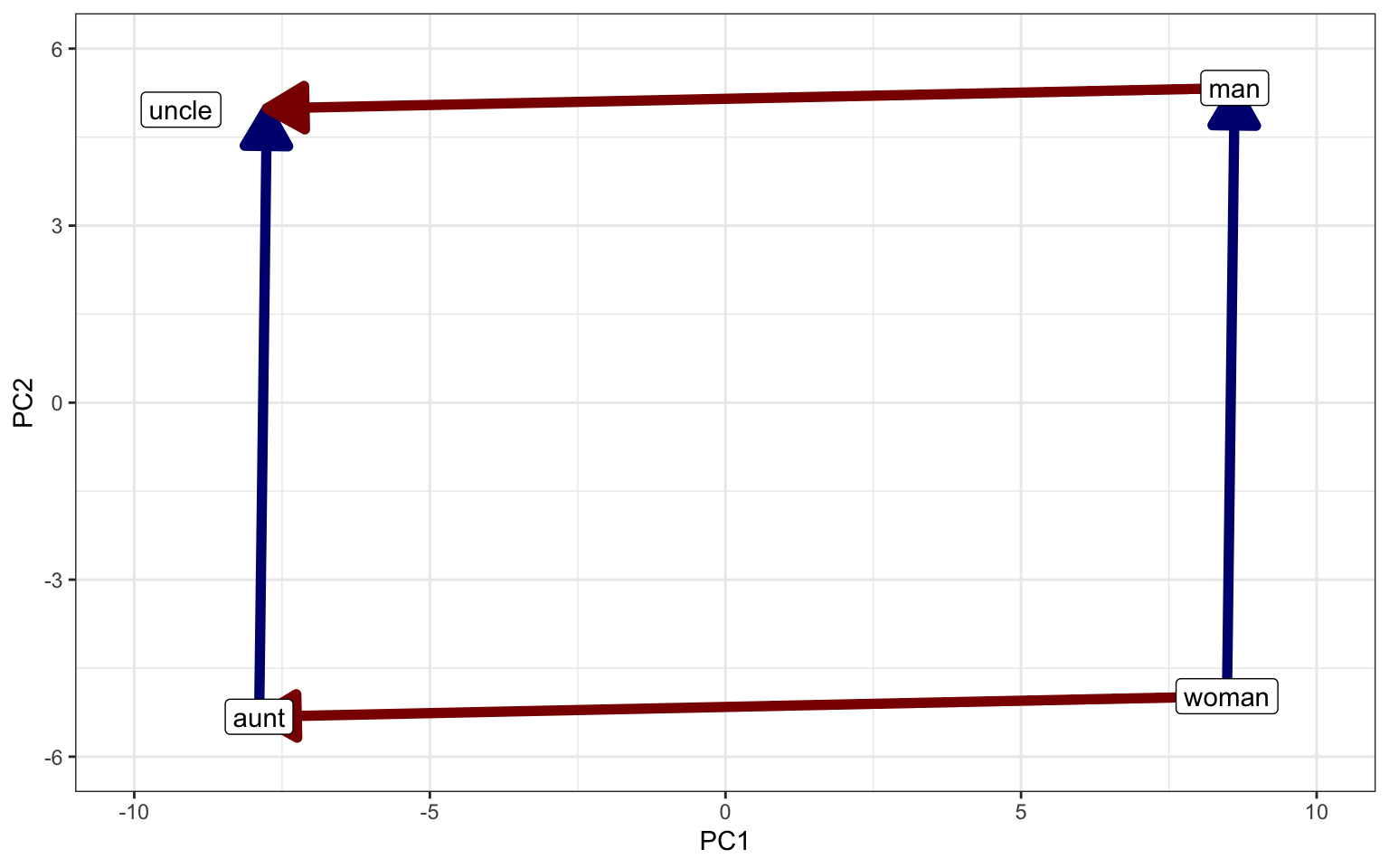
If we subtract the embedding of “man” from the embedding of “woman”, we get the vector shown in blue. This vector represents the move from male to female gender. A vector between two embeddings is called an anchored vector. So when we add the man-woman anchored vector to the embedding of “aunt”, we get very close to the embedding of “uncle”. This property was first noted in word2vec (Mikolov et al., 2013), and GloVe (Pennington et al., 2014) was specifically designed with it in mind.
Additive Analogies in Contextualized Embeddings
Notice that the analogical property relies on the magnitude of the vectors—if some vectors were shorter or longer than necessary, the parallelogram would not fit. This means that analogical reasoning may not be applicable to LLM embeddings, which are often organized in nonlinear patterns (Cai et al., 2021; Ethayarajh, 2019; Gao et al., 2019). Even specialized models like SBERT are generally not designed with the additive analogical property in mind (Reimers & Gurevych, 2019). Even though some geometrically motivated methods work fairly well in LLM embeddings, as we will see in Section 20.2.2.2, there is lots of room for improvement in this area.3
The simplest application of the analogical property is to complete analogies like “telescope is to astronomy as ________ is to psychology.” You can find word2vec’s answer to this puzzle by subtracting the embedding of “telescope” from the embedding of “astronomy”, adding the result to the embedding of “psychology”, and finding the embedding with the lowest Euclidean distance to that vector.
20.2.2 Anchored Vectors For Better Construct Representations
There is a fundamental problem with all embeddings that additive analogical reasoning can help us solve. Consider the embeddings for “happy” and “sad”. These may seem like opposites, but actually they are likely to be very close to each other in vector space because they both relate to emotional valence. This means that if we try to measure the happiness of words by comparing their embeddings to the embedding for “happy”, we will actually be measuring the extent to which the words relate to emotion in general. The word “depression” might seem happier than the word “table”, since depression is more emotion-related. This problem can be solved by using anchored vectors. Just like we created an anchored vector between “man” and “woman” to represent masculinity (as opposed to femininity), we can create an anchored vector between “happy” and “sad” to represent happiness (as opposed to sadness). As we saw in Section 20.2.1, anchored vectors can be applied wherever necessary in embedding space.
To measure constructs with an anchored vector, take the dot product of your text embeddings with the anchored vector. This is the equivalent of “projecting” the embeddings down onto the scale between one end of the anchored vector and the other.4
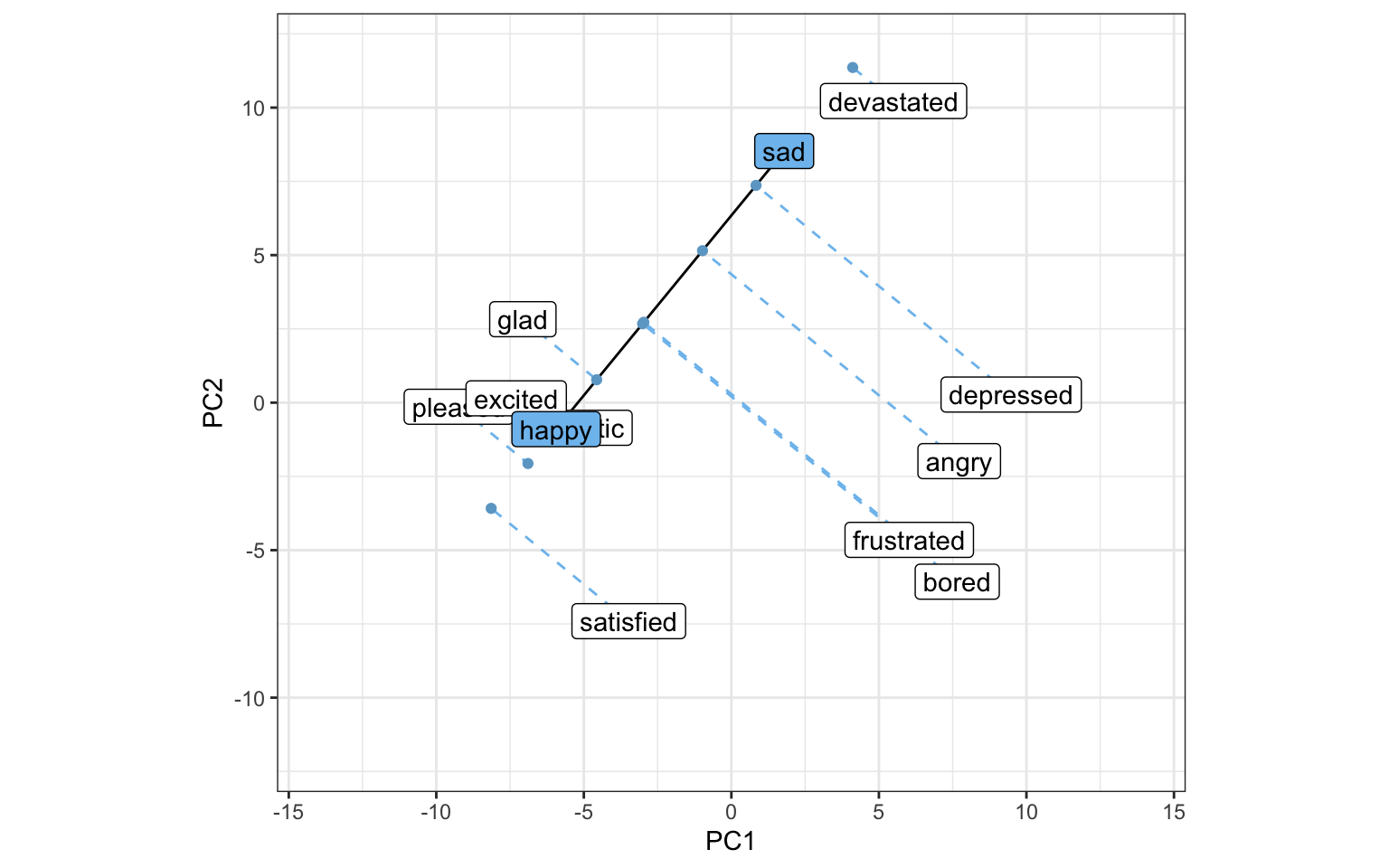
By projecting each embedding down onto the anchored vector between happy and sad, we create a scale from happy to sad.5 This is sometimes referred to as semantic projection (Grand et al., 2022).
20.2.2.1 Improving DDR With Anchored Vectors
In Section 14.4, we used two dictionaries to measure surprise as opposed to anticipation with word counts. By creating an anchored vector between surprise and anticipation, we can now replicate that analysis using DDR. The first step is to create a DDR for each dictionary. Since we already have one for surprise from Section 20.1.1, we just need to replicate the process for anticipation.
# get dictionary
anticipation_dict <- quanteda.sentiment::data_dictionary_NRC$anticipation
# word2vec embeddings of dictionary words
anticipation_ddr <- predict(word2vec_mod, anticipation_dict)
# average dictionary embedding (weighted by frequency)
anticipation_ddr <- anticipation_ddr |>
average_embedding(w = "trillion_word")We can now score the Hippocorpus texts by the dot product between their word2vec embeddings and the anchored vector, effectively projecting each one onto a scale between anticipation and surprise.
Since the scale is theoretically infinite (a text could have more surprise than the average dictionary embedding for surprise), we can analyze it with a standard linear regression.
surprise_mod_ddr_anchored <- lm(
surprise ~ memType,
data = hippocorpus_surprise_ddr_anchored
)
summary(surprise_mod_ddr_anchored)#>
#> Call:
#> lm(formula = surprise ~ memType, data = hippocorpus_surprise_ddr_anchored)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -3.502e+33 -3.502e+33 -2.349e+33 -1.876e+33 3.587e+35
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.876e+33 4.265e+32 4.399 1.1e-05 ***
#> memTyperecalled 1.626e+33 6.019e+32 2.702 0.00691 **
#> memTyperetold 4.728e+32 7.496e+32 0.631 0.52818
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 2.239e+34 on 6851 degrees of freedom
#> Multiple R-squared: 0.001101, Adjusted R-squared: 0.0008093
#> F-statistic: 3.775 on 2 and 6851 DF, p-value: 0.02298
We found a significant difference between imagined and recalled stories in the expected direction!
20.2.2.2 Improving CCR With Anchored Vectors
Remember the questionnaire-ness problem with CCR from Section 20.1.2? Anchored vectors can help us solve this problem. This time, let’s just negate each item from the surprise questionnaire, like this:
surprise_items_pos <- c(
"I was extremely surprised by the outcome of the event.",
"The outcome of the event was extremely interesting.",
"The outcome of the event was extremely new."
)
surprise_items_neg <- c(
"I was not surprised at all by the outcome of the event.",
"The outcome of the event was not interesting at all.",
"The outcome of the event was not new at all."
)This approach has the advantage of maintaining most of the original wording. By creating an anchored vector between the positive and negative CCRs, we can disregard this questionnaire-y wording, focusing only on the direction between lots of surprise and no surprise at all. Even though this approach makes big assumptions about the linearity of the contextualized embedding space (Section 20.2.1), it has been shown to work fairly well for a variety of constructs and models (Grand et al., 2022). It is particularly applicable to the Hippocorpus data, since the texts are first-person narratives about an event, just like the questionnaire items.
Let’s create the new anchored CCR and use it to reanalyze the Hippocorpus data.
# score documents by surprise
hippocorpus_surprise_ccr_anchored <- hippocorpus_sbert |>
get_sims(
Dim1:Dim384,
list(surprise = list(pos = surprise_ccr, neg = surprise_neg_ccr)),
method = "anchored"
)
# linear regression
surprise_mod_ccr_anchored <- lm(
surprise ~ memType,
hippocorpus_surprise_ccr_anchored
)
summary(surprise_mod_ccr_anchored)#>
#> Call:
#> lm(formula = surprise ~ memType, data = hippocorpus_surprise_ccr_anchored)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.225990 -0.040223 -0.000665 0.039302 0.238119
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 0.962342 0.001109 867.629 memTyperecalled 0.005910 0.001565 3.775 0.000161 ***
#> memTyperetold 0.007031 0.001950 3.607 0.000312 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.05823 on 6851 degrees of freedom
#> Multiple R-squared: 0.00283, Adjusted R-squared: 0.002539
#> F-statistic: 9.721 on 2 and 6851 DF, p-value: 6.083e-05
We found a significant difference between imagined and recalled stories such that recalled stories had more surprising content (p < .001)! We also found that retold stories had more surprising content than imagined stories (p < .001). These results support Sap et al.’s hypothesis that true autobiographical stories would include more surprising events than imagined stories.
An example of using anchored vectors and CCR in research: Simchon et al. (2023) collected 10,000 posts from the r/depression subreddit, along with a control group of 100 posts each from 100 randomly selected subreddits. They then used a variant of SBERT, all-MiniLM-L6-v2 (see Chapter 19), to compute CCR embeddings of a psychological questionnaire measuring “locus of control,” the feeling that you have control over your own life. The questionnaire included items measuring an internal locus of control (“I have control”), and items measuring an external locus of control (“External forces have control”). Simchon et al. constructed an anchored vector to capture the direction between internal and external locus of control, and projected embeddings of the Reddit posts onto that vector to measure how much each post reflected an internal vs. an external locus of control. They found that posts in r/depression exhibited a more external locus of control than posts in the control group.
20.2.3 Correlational Anchored Vectors
In Section 15.4, we used the Crowdflower Emotion in Text dataset to generate a new dictionary for the emotion of surprise. We can use a similar approach to generate an anchored vector. Remember that the anchored vector for surprise is simply a direction in the embedding space. Rather than finding this direction by subtracting a negative construct embedding from a positive one (as we did in Section 20.2.2.2 and Section 20.2.2.2), we can use machine learning to find the direction that best represents surprise in a training dataset.
To train an anchored vector on the Crowdflower dataset, we will first need to embed its 40,000 Twitter posts. We will do this just as we did for the Hippocorpus texts in Section 18.3.1.
# data from https://data.world/crowdflower/sentiment-analysis-in-text
crowdflower <- read_csv("data/text_emotion.csv") |>
rename(text = content) |>
mutate(
doc_id = as.character(tweet_id),
surprise = if_else(sentiment == "surprise", "surprise", "no surprise"),
surprise = factor(surprise, levels = c("no surprise", "surprise"))
)
# word2vec document embeddings
crowdflower <- crowdflower |>
embed_docs("text", word2vec_mod, id_col = "doc_id", .keep_all = TRUE)With Partial Least Squares (PLS) regression (Mevik & Wehrens, 2007; Wold et al., 2001), which finds directions in the feature space that best correlate with the dependent variable (in this case, surprise), we can create a correlational anchored vector.
#> Loading required package: lattice
#>
#> Attaching package: 'caret'
#> The following object is masked from 'package:purrr':
#>
#> lift
set.seed(2024)
pls_surprise <- train(
surprise ~ .,
data = select(crowdflower, surprise, dim_1:dim_300),
method = "pls",
scale = FALSE, # keep original embedding dimensions
trControl = trainControl("cv", number = 10), # cross-validation
tuneLength = 1 # only 1 component (our anchored vector)
)
surprise_anchored_pls <- pls_surprise$finalModel$projection[,1]With the new correlational anchored vector, we can redo our analysis from Section 20.1.1.
# score documents by surprise
hippocorpus_surprise_anchored_pls <- hippocorpus_word2vec |>
get_sims(
dim_1:dim_300,
list(surprise = surprise_anchored_pls),
method = "dot_prod"
)
surprise_mod_anchored_pls <- lm(
surprise ~ memType,
data = hippocorpus_surprise_anchored_pls
)
summary(surprise_mod_anchored_pls)#>
#> Call:
#> lm(formula = surprise ~ memType, data = hippocorpus_surprise_anchored_pls)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -1.965e+34 -1.965e+34 -1.318e+34 -1.053e+34 2.013e+36
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.053e+34 2.393e+33 4.399 1.1e-05 ***
#> memTyperecalled 9.126e+33 3.378e+33 2.702 0.00691 **
#> memTyperetold 2.654e+33 4.207e+33 0.631 0.52818
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 1.256e+35 on 6851 degrees of freedom
#> Multiple R-squared: 0.001101, Adjusted R-squared: 0.0008093
#> F-statistic: 3.775 on 2 and 6851 DF, p-value: 0.02298
Once again we find significant results in support of Sap et al. (2022)!
20.2.4 Machine Learning Methods
After Section 20.2.3, you may wonder why we stopped at a single direction in embedding space. Why not go all out with the machine learning? If you wondered this, great job! Psychologists are increasingly training machine learning algorithms on text embeddings to quantify relevant constructs (Kjell et al., 2022). Indeed, this is the approach used to generate the cover of this book.
With machine learning approaches, the nonlinearity of contextualized embedding spaces becomes less of a problem. Given enough training data, we can specify a model that can capture nonlinear patterns, such as a support vector machine. We could also simultaneously use embeddings from multiple layers of the LLM with aggregation_from_layers_to_tokens = "concatenate" in textEmbed(). Some research advises using both the [CLS] token and an average of the other token embeddings as input to the machine learning model (Lee et al., 2023). There is no blanket rule about which machine learning algorithms work best with embeddings, but Kjell et al. (2022) recommend ridge regression for continuous outputs, and random forest for classification. If you are not comfortable fitting machine learning algorithms in R, you can use the convenience function, textTrain(), provided by the text package. In the example code below, we train a random forest model on the Crowdflower dataset, and use it to identify surprise in the Hippocorpus texts.
library(text)
# embed Hippocorpus texts
hippocorpus_subset_distilroberta <- textEmbed(
hippocorpus_df$story,
model = "distilroberta-base",
layers = c(-2, -1), # last two layers
# aggregate token embeddings in each layer, then concatenate layers
aggregation_from_tokens_to_texts = "mean",
aggregation_from_layers_to_tokens = "concatenate",
dim_name = FALSE,
keep_token_embeddings = FALSE
)
# load training set
set.seed(2024)
crowdflower_subset <- crowdflower |>
select(doc_id, text, surprise) |>
group_by(surprise) |>
slice_sample(n = 2000)
# embed training set
crowdflower_subset_distilroberta <- textEmbed(
crowdflower_subset$text,
model = "distilroberta-base",
layers = c(-2, -1), # last two layers
# aggregate token embeddings in each layer, then concatenate layers
aggregation_from_tokens_to_texts = "mean",
aggregation_from_layers_to_tokens = "concatenate",
dim_name = FALSE,
keep_token_embeddings = FALSE
)
# fit random forest model
surprise_randomforest <- textTrain(
x = crowdflower_subset_distilroberta$texts$texts,
y = crowdflower_subset$surprise
)
# predict on Hippocorpus texts
surprise_pred <- textPredict(
surprise_randomforest,
hippocorpus_subset_distilroberta$texts$texts
)An example of using embedding-based machine learning models trained in research: Chersoni et al. (2021) used PLS regression to map word embeddings from various models (including word2vec, fastText, GloVe, and BERT) to human-rated semantic features derived from research in cognitive psychology. By comparing the performance of the different models, they could draw inferences about the types of information encoded in words. They found that cognition, causal reasoning, and social content were best predicted across models. General categories (e.g. vision, arousal) tended to be better predicted than specific characteristics (e.g. dark, light, happy, sad).
Atari, M., Omrani, A., & Dehghani, M. (2023). Contextualized construct representation: Leveraging psychometric scales to advance theory-driven text analysis. PsyArXiv. https://doi.org/10.31234/osf.io/m93pd
Cai, X., Huang, J., Bian, Y., & Church, K. (2021). Isotropy in the contextual embedding space: Clusters and manifolds. International Conference on Learning Representations. https://openreview.net/forum?id=xYGNO86OWDH
Chersoni, E., Santus, E., Huang, C.-R., & Lenci, A. (2021). Decoding word embeddings with brain-based semantic features. Computational Linguistics, 47(3), 663–698. https://doi.org/10.1162/coli_a_00412
Choi, D., & Choi, I. (2010). A comparison of hindsight bias in groups and individuals: The moderating role of plausibility. Journal of Applied Social Psychology, 40(2), 325–343. https://search.ebscohost.com/login.aspx?direct=true&db=sxi&AN=48116256&site=ehost-live
Choi, I., & Nisbett, R. E. (2000). Cultural psychology of surprise: Holistic theories and recognition of contradiction. Journal of Personality and Social Psychology, 79(6), 890–905.
Ethayarajh, K. (2019). How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings. https://arxiv.org/abs/1909.00512
Gao, J., He, D., Tan, X., Qin, T., Wang, L., & Liu, T.-Y. (2019). Representation degeneration problem in training natural language generation models. https://arxiv.org/abs/1907.12009
Garten, J., Hoover, J., Johnson, K. M., Boghrati, R., Iskiwitch, C., & Dehghani, M. (2018). Dictionaries and distributions: Combining expert knowledge and large scale textual data content analysis: Distributed dictionary representation. Behavior Research Methods, 50, 344–361.
Grand, G., Blank, I. A., Pereira, F., & Fedorenko, E. (2022). Semantic projection recovers rich human knowledge of multiple object features from word embeddings. Nature Human Behaviour, 6(7), 975–987. https://doi.org/10.1038/s41562-022-01316-8
Kjell, O., Sikström, S., Kjell, K., & Schwartz, H. (2022). Natural language analyzed with AI-based transformers predict traditional subjective well-being measures approaching the theoretical upper limits in accuracy. Scientific Reports, 12, 3918. https://doi.org/10.1038/s41598-022-07520-w
Lee, K., Choi, G., & Choi, C. (2023). Use all tokens method to improve semantic relationship learning. Expert Systems with Applications, 233, 120911. https://doi.org/https://doi.org/10.1016/j.eswa.2023.120911
Li, B., Zhou, H., He, J., Wang, M., Yang, Y., & Li, L. (2020). On the sentence embeddings from pre-trained language models. https://arxiv.org/abs/2011.05864
Mevik, B.-H., & Wehrens, R. (2007). The pls package: Principal component and partial least squares regression in r. Journal of Statistical Software, 18(2), 1–23. https://doi.org/10.18637/jss.v018.i02
Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic regularities in continuous space word representations. In L. Vanderwende, H. Daumé III, & K. Kirchhoff (Eds.), Proceedings of the 2013 conference of the north American chapter of the association for computational linguistics: Human language technologies (pp. 746–751). Association for Computational Linguistics. https://aclanthology.org/N13-1090
Mohammad, S. M., & Turney, P. D. (2013). Crowdsourcing a word-emotion association lexicon. Computational Intelligence, 29(3), 436–465.
Mohammad, S., & Turney, P. (2010). Emotions evoked by common words and phrases: Using Mechanical Turk to create an emotion lexicon. Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, 26–34. https://aclanthology.org/W10-0204
Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. Empirical Methods in Natural Language Processing (EMNLP), 1532–1543. http://www.aclweb.org/anthology/D14-1162
Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In K. Inui, J. Jiang, V. Ng, & X. Wan (Eds.), Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) (pp. 3982–3992). Association for Computational Linguistics. https://doi.org/10.18653/v1/D19-1410
Sap, M., Jafarpour, A., Choi, Y., Smith, N. A., Pennebaker, J. W., & Horvitz, E. (2022). Quantifying the narrative flow of imagined versus autobiographical stories. Proceedings of the National Academy of Sciences, 119(45), e2211715119. https://doi.org/10.1073/pnas.2211715119
Simchon, A., Hadar, B., & Gilead, M. (2023). A computational text analysis investigation of the relation between personal and linguistic agency. Communications Psychology, 1–9. https://doi.org/10.1038/s44271-023-00020-1
Wold, S., Sjöström, M., & Eriksson, L. (2001). PLS-regression: A basic tool of chemometrics. Chemometrics and Intelligent Laboratory Systems, 58, 109–130. https://api.semanticscholar.org/CorpusID:11920190
For more information on this property, see our footnote in Section 18.3.1. Note that this property emerges naturally from the way decontextualized models like word2vec and GloVe are trained, and therefore may not hold true for contextualized embeddings.↩︎
Cosine similarity is appropriate here because our contextualized embeddings were generated by an SBERT model, which was designed to be used with cosine similarity. If we had used another model such as RoBERTa, Euclidean distance might be more appropriate.↩︎
There are some promising methods for getting more geometrically regular embeddings out of LLMs. For example, averaging the last two layers of the model seems to help (Li et al., 2020). Taking a different approach, Ethayarajh (2019) created static word embeddings from an LLM by running it on a large corpus and taking the set of each word’s contextualized representations from all the places it appears in the corpus. The loadings of the first principal component of this set represent the dimensions along which the meaning of the word changes across different contexts. These loadings can themselves be used as a vector embedding which can out-perform GloVe and FastText embeddings on many word vector benchmarks, including analogy solving. This approach worked best for embeddings from the early layers of the LLM.↩︎
For an intuitive explanation of why the dot product is equivalent to a projection, see 3blue1brown’s video on the subject.. Incidentally, the dot product with the anchored vector is also equivalent to the dot product with the positive embedding (e.g. “happy”) minus the dot product with the negative vector (e.g. “sad”).↩︎
Taking the dot product with an anchored vector yields an unstandardized version of this scale. If you want “sad” to be 0 and “happy” to be 1 on the scale, use the
anchored_sim()function included in our Github repo.↩︎